ログ設計はSpring Bootの障害調査から逆算する
Spring Boot ログ設計で迷う場面は、実務ではかなり多いです。INFOとDEBUGをどう使い分けるか。例外ログをどこで出すか。リクエスト単位で追跡できるようにするか。JSONログにするべきか。こうした判断は、運用を始めてから効いてきます。
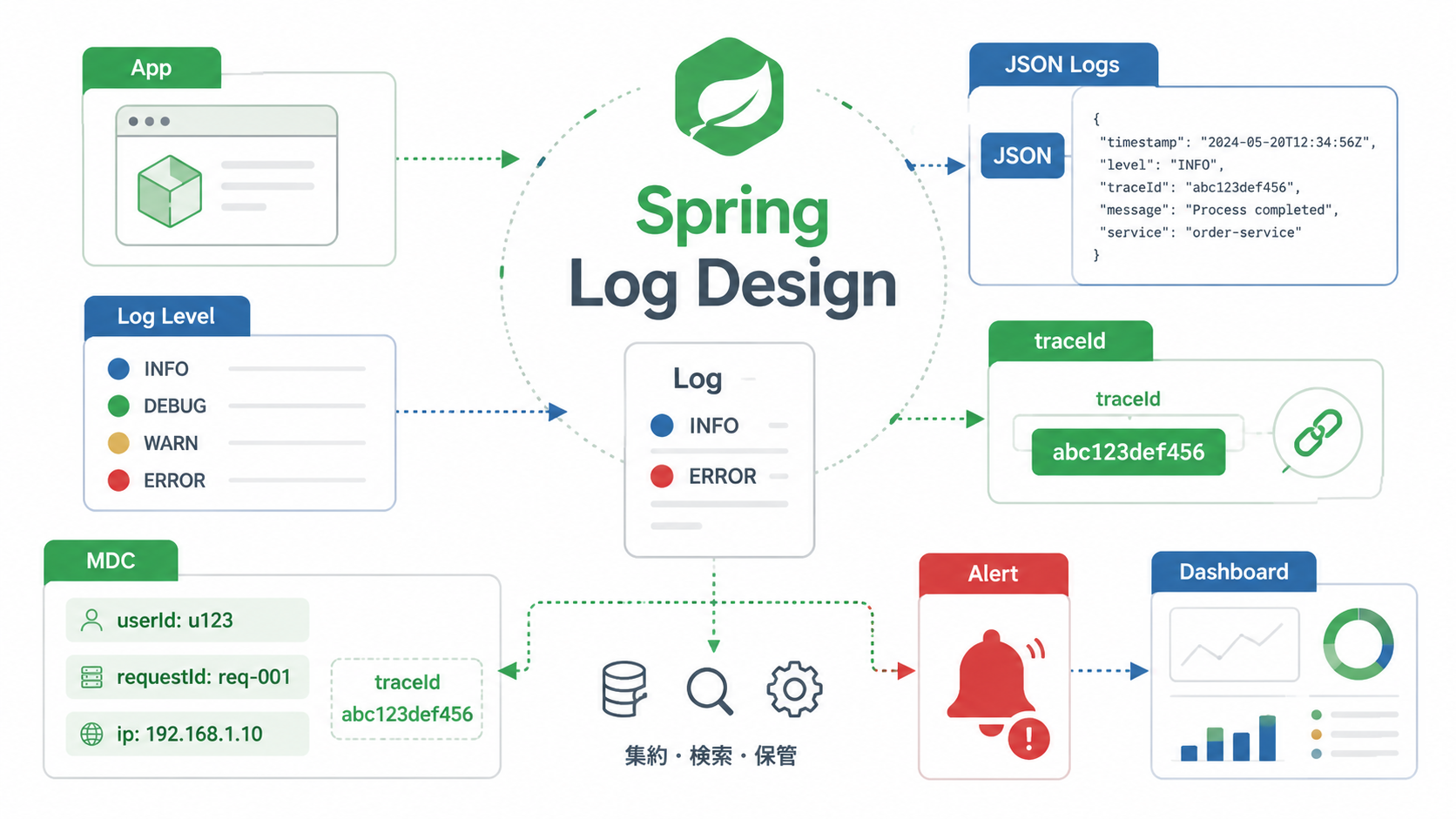
結論から言うと、ログは「出せばよい」ものではありません。まず、障害調査、監査、性能確認、監視連携のどれに使うログなのかを決めます。そのうえで、ログレベル、出力項目、構造化、相関ID、例外ログ方針を設計します。
この記事では、Java/Spring Bootの実務で使いやすいログ設計の考え方を整理します。扱うのは、Logback、ログレベル、MDC、traceId、構造化ログ、例外ログ、個人情報の扱いです。レビューで見られやすいポイントも取り上げます。
目的別にログ設計を分ける
まず、ログ設計では目的を分けます。目的が曖昧なままログを追加すると、開発中は便利でも、本番運用ではノイズになります。
実務では、少なくとも次の4つに分けて考えると整理しやすくなります。
- 障害調査: どの処理で、何が、どの入力条件で失敗したかを追う
- 監査: 誰が、いつ、どの重要操作を行ったかを残す
- 性能確認: 外部API、DB、バッチ、重い処理の所要時間を見る
- 監視連携: ERROR件数、特定イベント、異常傾向を検知する
例えば、障害調査用のログにはリクエストID、ユーザーID、処理名、例外情報が必要です。一方で、監査ログでは操作対象や実行者が重要になります。性能確認では、処理時間や外部サービス名を見ます。
このように目的ごとに必要な項目を分けると、「とりあえず全部INFOで出す」状態を避けやすくなります。
ログ設計ではログレベルの基準を決める
次に、ログレベルの基準をチームで揃えます。Spring Bootでは標準でログ出力の仕組みが用意されています。公式のLoggingリファレンスでも、ログ設定や出力形式が説明されています。便利な反面、基準がないとINFOやERRORの意味がプロジェクト内でぶれます。
目安として、業務アプリでは次のように考えるとレビューしやすくなります。
- ERROR: ユーザー影響、データ不整合、外部連携失敗など、調査や通知が必要な失敗
- WARN: 処理は継続できるが、放置すると問題になる可能性がある状態
- INFO: 業務上重要なイベント、起動停止、バッチ開始終了、外部連携の結果
- DEBUG: 開発や調査時にだけ見たい詳細情報
- TRACE: 通常の業務開発では限定的に使う非常に細かい情報
INFOは「本番で常時出してもよい情報」に絞ります。リクエストごとの細かい分岐、Entityの中身、SQLパラメータを何でもINFOにすると、ログ量が増えます。その結果、必要な情報を探しにくくなります。
ERRORも注意が必要です。ハンドリング済みの入力エラーまでERRORにすると、監視アラートが疲弊します。バリデーションエラー、認可エラー、404などは分けて扱います。システム異常なのか、通常の業務イベントなのかを判断します。
相関IDとMDCをログ設計に入れる
本番障害で困りやすいのは、「1つのリクエストに関係するログをまとめて追えない」状態です。複数ユーザーのログが混ざると、処理の流れを追うだけで時間がかかります。Controller、Service、Repository、外部API呼び出しを順番に確認する必要があるためです。
そのため、リクエストIDやtraceIdをログに含めます。Spring Boot ログ設計では、FilterやInterceptorで相関IDを生成します。その値をMDCに入れる方法がよく使われます。
@Component
public class RequestIdFilter extends OncePerRequestFilter {
private static final String REQUEST_ID = "requestId";
@Override
protected void doFilterInternal(
HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain
) throws ServletException, IOException {
String requestId = Optional.ofNullable(request.getHeader("X-Request-Id"))
.filter(id -> !id.isBlank())
.orElse(UUID.randomUUID().toString());
MDC.put(REQUEST_ID, requestId);
response.setHeader("X-Request-Id", requestId);
try {
filterChain.doFilter(request, response);
} finally {
MDC.remove(REQUEST_ID);
}
}
}MDCに入れた値は、ログパターンやJSONログのフィールドとして出力します。これにより、ログ検索基盤で requestId や traceId を条件に絞り込めます。
ただし、MDCはスレッドローカルに依存します。そのため、非同期処理では引き継ぎ方を確認する必要があります。@Async、スケジューラ、メッセージキュー、リアクティブ処理では、同じ前提で扱えないことがあります。
検索と監視を前提に構造化ログを選ぶ
Spring Boot 3.4以降では、公式に構造化ログがサポートされています。Spring BootのLoggingリファレンスでは、ECS、GELF、Logstash形式への対応が説明されています。logging.structured.format.console や logging.structured.format.file で形式を指定できます。Spring公式ブログのStructured logging in Spring Boot 3.4でも概要が紹介されています。
# application-prod.yml
logging:
structured:
format:
console: ecs構造化ログを使うと、message、log.level、service.name、traceId、userId などをフィールドとして扱えます。全文検索だけに頼らず、条件指定で調査できるのが大きな利点です。
一方で、JSONログにすれば自動的に運用しやすくなるわけではありません。フィールド名、出力するID、個人情報の扱いを決める必要があります。ログ基盤側のインデックス設計や保存期間も含めて考えます。
例外ログは出す場所を絞る
例外ログでよくある問題は、同じ例外が何度も出力されることです。Repository、Service、ControllerAdviceの各層でERRORを出すと、1つの障害が複数のERRORとして見えます。
基本は、例外を握りつぶさず、最終的にハンドリングする場所でログを出します。Web APIであれば、@RestControllerAdvice のような共通例外ハンドラを使います。想定外例外をERRORとして記録する設計が扱いやすいです。
@RestControllerAdvice
public class ApiExceptionHandler {
private static final Logger log =
LoggerFactory.getLogger(ApiExceptionHandler.class);
@ExceptionHandler(Exception.class)
ResponseEntity<ErrorResponse> handleUnexpected(Exception e) {
log.error("Unexpected error occurred", e);
return ResponseEntity.internalServerError()
.body(new ErrorResponse("INTERNAL_SERVER_ERROR"));
}
}業務例外やバリデーションエラーは、ERRORにしない判断もあります。例えば、在庫不足、入力値不正、権限不足は、業務上の結果として扱うことが多いです。この場合はINFOまたはWARNにするか、レスポンスだけ返してログを出さない選択もあります。
重要なのは、監視対象にするERRORを絞ることです。ERRORが多すぎると、本当に対応すべき障害に気づきにくくなります。
出してはいけない情報もログ設計で決める
Spring Boot ログ設計では、何を出すかだけでなく、何を出さないかも重要です。ログは長く保存されます。開発者、運用担当、外部サービスから参照されることもあります。
特に、次の情報は原則としてログにそのまま出さない方針にします。
- パスワード、トークン、APIキー、セッションID
- クレジットカード番号、口座番号、本人確認情報
- 過剰な個人情報、住所、電話番号、生年月日
- リクエストボディ全体、外部APIレスポンス全体
調査に必要な場合でも、マスキング、ハッシュ化、ID化を検討します。例えばユーザー特定にはメールアドレスそのものではなく、ユーザーIDを出す方が安全です。
また、toString() の実装にも注意します。DTOやEntityをそのままログに出すと、意図せず機密情報が含まれることがあります。レビューでは、ログ出力行だけを見て終わらせません。渡しているオブジェクトの中身まで確認します。
環境ごとにログ設計の設定を分ける
ログ設計は、ローカル、検証環境、本番環境で同じにする必要はありません。目的に応じて変えるのが自然です。
ローカルでは読みやすいコンソールログを重視します。検証環境ではDEBUGを一時的に上げられるようにします。本番環境では、INFO以上を基本にし、JSONログやログ基盤連携を優先します。
# application.yml
logging:
level:
root: info
com.example: info
---
spring:
config:
activate:
on-profile: local
logging:
level:
com.example: debugSpring BootのLogging How-toでは、LogbackやLog4j2の設定、ファイル出力、構成の考え方が説明されています。独自の logback-spring.xml を使う場合も注意が必要です。環境ごとの設定が複雑になりすぎないようにします。
レビューで見るログ設計のポイント
ログ設計は、コードレビューでも差が出ます。動作確認だけでは問題が見えにくく、運用時に初めて困ることが多いためです。
レビューでは、次の観点を確認すると実務的です。
- INFOログが本番で常時出ても問題ない粒度になっているか
- ERRORログが監視対象として意味のある失敗に絞られているか
- 例外ログが重複して出ていないか
- requestId、traceId、userIdなど、調査に必要なキーが入っているか
- パスワード、トークン、個人情報が出ていないか
- 外部APIやDBなど、遅延原因になりやすい処理の時間が追えるか
- 構造化ログのフィールド名がチーム内で揃っているか
特に、外部API連携やバッチ処理では、成功時のログも重要です。失敗時だけログを出すと、処理の進み具合が追いにくくなります。「何件処理したのか」「いつから遅くなったのか」も見えにくくなります。
よくある質問
Logbackは標準構成のままでよいですか?
多くのSpring Bootアプリケーションでは、まず標準構成のLogbackで十分です。ログ設計で重要なのは、ロギングライブラリを変えることよりも、ログレベル、出力項目、例外ログ、構造化、監視連携の方針を決めることです。要件によってLog4j2などを選ぶこともありますが、運用要件から判断します。
SQLログは本番で出してもよいですか?
本番でSQLログを常時DEBUG相当で出すのは慎重に判断します。ログ量が増えやすく、パラメータに機密情報が含まれる可能性もあります。性能調査が必要な場合は、期間や対象を絞ります。APMやDB側の監視、スロークエリログも活用します。
JSONログは必ず導入するべきですか?
必須ではありません。ただし、ログ基盤で検索、集計、アラート化するなら有効です。小規模なアプリケーションやローカル開発では、テキストログの方が読みやすいこともあります。本番運用でログ検索基盤に流すなら、構造化ログを検討する価値があります。
まとめ
Spring Boot ログ設計では、ログをただ増やすのではなく、運用で使える情報に絞ることが重要です。障害調査、監査、性能確認、監視連携という目的を分け、ログレベルと出力項目を決めます。
また、requestIdやtraceIdでリクエスト単位に追跡できるようにし、必要に応じて構造化ログを導入します。例外ログは出す場所を絞り、個人情報やトークンを出さない方針も明確にします。
Java/Spring Boot案件では、実装だけでなく、運用や障害調査まで見据えた設計力が評価されます。ログ設計、例外処理、監視、レビュー観点まで含めて経験を活かす場面があります。次の環境選びでも、その強みを整理しておくとよいです。
一度カジュアル面談をしませんか?
株式会社bluenaは「高還元」と「伴走支援」を両立したSES企業です。単価の81〜86%を還元する報酬体系と、専任サポーターによる隔週1on1で、エンジニアが納得できるキャリアを実現します。
まとまっていなくてもOK——まずは現在地を聞かせてください。
カジュアル面談ですので、お気軽にお聞かせください。